I have put a lot of effort into a feature that I don’t even use: graphical emoticons. As usual, the small issue resulted in a large code refactoring. I had the task of fixing regression bugs from Pidgin 2.x.y, so I took care of broken remote smileys. It’s a pleasant feature, that allows defining the list of custom smileys to use in outgoing messages. If we send one in our message and the remote client doesn’t have it, the image will be automatically transferred. For protocols not supporting this feature, the bare textual representation will be shown instead of the picture.
The code responsible for emoticon handling was horrid. In 2.x.y branch it was already quite messy, but became even worse after replacing GtkIMHtml with WebKitGTK for displaying a conversation. The problem was, the old parsing code was optimised to be used with GtkIMHtml. It was totally incompatible with WebKitGTK, so the GSoC student who did a conversion made his own provisional smiley parser. It just added insult to injury.
Inline images
Both GtkIMHtml and WebKitGTK use purple’s “stored images” to provide data for emoticon smiley. It’s a generic container to hold raw image file contents, without any decoding. Its main purpose was pretty simple: to reference this data by a single integer number. Thus, an image may be embedded in HTML with <img src="purple-image:5">. It’s quite convenient, but the API was a bit messy. Not that bad, but we had plans to convert it to a GObject. Instead of duplicating the exact behavior of the old implementation, I took the usual way: I wrote entirely new PurpleImage class, much richer, but also simpler to use.
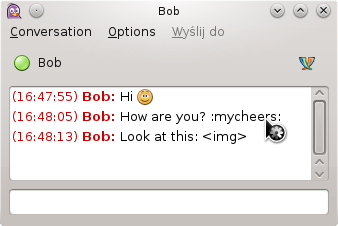
PurpleImages, aside from the old simple referencing feature, have several new ones. Remote images support is the one which improves end-user experience the most. It allows defining an empty image and providing a data for it later. Now, if we receive a message with an inline image embedded (not necessarily a smiley), it will be displayed without it and the image will be shown when ready – just like its done in web browsers. It heavily impacts protocol plugins: with the old API, they had to queue messages and wait for images being transferred. Now, it’s fully handled by libpurple. By the chance of deploying it, I fixed inline images support in every protocol that had it.
Tries
As I mentioned before, the smiley parser for 3.0.0 branch was provisional and the old one was not suitable for WebKitGTK. GtkIMHtml (a Pidgin 2.x.y component, despite its Gtk namespace) exposed its internal parsing mechanism and allowed to process every literal in parsed HTML. Thereby, a libpurple routine was called on every word and replaced them into an image, if hit the emoticon. The lookup was quite fast, because of trie-like implementation of GtkSmileyTree.

A Trie is a tree structure for holding multiple strings and searching them by prefixes. The primary idea of trie is that two strings with the common prefix will share the part of tree for the common segment and branch out the remaining parts. It’s only a fundamental part of structure, which may be used for completely different purposes. In fact, it was used both in the old GtkSmileyTree and my new smiley parser implementation. Except for this single similarity, these two are barely related.
Instead of writing fat-but-fast smiley parser, I decided to implement independent PurpleTrie class – a trie-based text search algorithm. It allows for searching multiple strings in multiple source texts in a linear time! To be precise, it needs O(m) time for building a trie (where m is the total length of provided patterns) and O(n) time for searching (where n is the length of source text). The frequency of patterns in a text doesn’t affect this value. The best thing in that structure is, it may also be used in libpurple plugins.
For a contrast, the interim smiley parser implementation was not focused on performance at all. Its search time could be estimated as O(n * m * t), where n is the number of smileys, m is their length (assuming smileys are equal-length – in the real-world case the formula would be more complicated) and t is the text length. It’s that bad, mainly because every supported (not necessarily inserted into a text) smiley is parsed separately. The m * t part depends on strstr implementation, but for the better ones we could find another similarly bad instance of smileys configuration. With such bad complexity, it could even be exploited for a denial-of-service attack.
What’s next?
In 3.0.0 branch there were a lot of smiley- and image-related issues and I haven’t described all of them. But I hope I fixed all of them. You can look for details in our hg, in smiley-related commits between 302a7cb4c1ab and d598e7950c34. Now, I am focused on the permanent issue – the Windows version.
Nice work!